
L’annotation d’images est considérée comme une tâche critique dans l’apprentissage automatique supervisé, car elle constitue l’un des moyens de créer des modèles plus fiables. Par définition, l’annotation d’images est le processus d’étiquetage avec des informations de métadonnées et des attributs pour montrer les caractéristiques d’intérêt que le modèle doit être entraîné à reconnaître par lui-même.
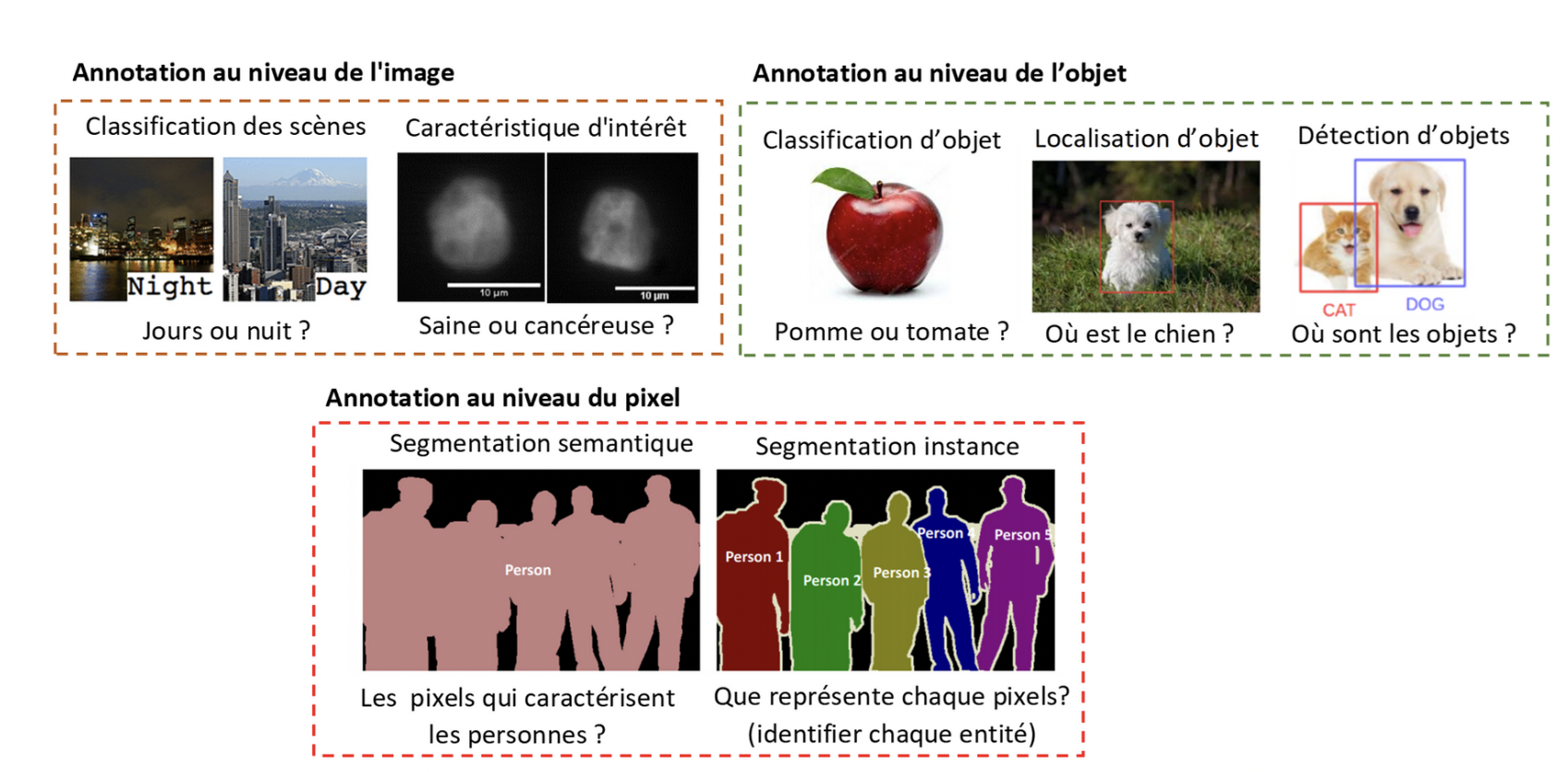
Il existe trois différents types d’annotation d’images: au niveau de l’image, au niveau de l’objet et le niveau du pixel, dont la complexité varie en fonction de la tâche à accomplir (figure 1). Le premier type est simple et se fait au niveau global de l’image pour classifier la présence ou non d’une caractéristique d’intérêt particulière ou détecter un type de scène spécifique. Cependant, l’annotation au niveau des objets est effectuée à l’intérieur des images avec un niveau de complexité modéré. Elle consiste à étiqueter l’image en fonction de l’objet d’intérêt qu’elle contient, ou à marquer les objets avec des boîtes de délimitation (bounding boxes) pour les applications de détection et de localisation d’objets. L’annotation la plus complexe parmi les trois types est celle au niveau du pixel. Cette opération consiste à délimiter les frontières entre les objets (régions) et à les étiqueter sous une identification « identique ou différente » pour les tâches de segmentation (sémantique ou par instance).
Plusieurs méthodes existent pour simplifier et accélérer la tâche d’annotation d’images, notamment des méthodes assistées par l’humain et des méthodes assistées par ordinateur. Nous aborderons ces méthodes dans la suite de cet article.
Les méthodes d’annotation d’images assistées par humain consistent à paralléliser le travail entre plusieurs annotateurs pour rendre la tâche d’annotation d’images plus rapide et plus fiable. Il existe trois solutions : «In-house», «Outsourcing» et en « Crowdsourcing ».
La solution In-house consiste à gérer les projets d’annotation d’images avec les ressources disponibles au sein d’un établissement. Le processus d’annotation peut être confié à des annotateurs internes au sein de l’équipe ou être annoté par soi-même s’il s’agit d’un projet expérimental à petite échelle. L’Outsourcing est la solution qui consiste à confier l’annotation à des experts externes ayant l’expérience requis pour fournir des résultats de qualité. Et en Crowdsourcing, le processus d’annotation peut se faire d’une manière collaborative via des portails en ligne gratuits tels que Cytomine, LabelMe, etc. D’autres plateformes commerciales divisent l’annotation en micro-tâches et assignent chacune de ces tâches à un collaborateur (annotateur). ClickWorker et Amazon Mechanicalturk sont des exemples de telles plateformes.
Outre la parallélisation à plusieurs annotateurs, la tâche d’annotation peut également être effectuée en totalité ou en partie à l’aide de l’ordinateur. L’une de ces méthodes repose sur l’utilisation de plateformes d’annotation guidées par l’apprentissage automatique (annotation faiblement supervisée). Elles permettent de dessiner simplement les étiquettes avec la souris afin d’entraîner un algorithme classique tel que le Random Forest. Une correction manuelle est ensuite effectuée sur les résultats obtenus pour générer les annotations finales. Exemples de ces plateformes open source : Ilastik, Phenotiki, etc.
De même, l’augmentation des données est une autre solution couramment utilisée pour fournir automatiquement des données avec une vérité terrain. Elle peut être réalisée par des techniques de manipulation d’images en effectuant des transformations sur les images annotées disponibles. Ces transformations peuvent être géométriques, photométriques, ajout de bruit, etc.
Les bibliothèques python les plus utilisées sont « ImageDataGenerator » dans « Keras » et « albumentations ».
Finalement, l’annotation encore peut être réalisée par la simulation numérique. Cette stratégie consiste à utiliser des données synthétiques dont la vérité terrain (annotation) est générée automatiquement pour entraîner des modèles d’apprentissage automatique. Ces modèles seront ensuite utilisés pour analyser des images réelles. Un exemple de simulateur d’images est MicroVIP, une plateforme de simulation d’images microscopiques.
En conclusion, il existe un certain nombre de méthodes pour faciliter et accélérer l’annotation d’images. Malgré leurs avantages, ces méthodes peuvent entraîner certains coûts. Pour les méthodes assistées par l’humain, certaines sont gratuites, alors que d’autres sont payantes. Concernant la confidentialité des données, certaines plateformes sont dotées d’un environnement réservé à la protection des données. D’autres fournisseurs de service d’annotation s’engagent à ce que les données soient effacées de leurs serveurs après les annotations.
Pour les méthodes assistées par ordinateur, un petit nombre d’images annotées manuellement sont requises comme point de départ pour des méthodes telles que l’augmentation des données. D’autres méthodes, comme la simulation numérique, nécessitent une connaissance approfondie des phénomènes physiques contribuant à la formation de l’image et ses conditions d’acquisition, afin de générer des images réalistes.
